Most B2B SEO programs don’t plateau because content stops working they plateau because the delivery system becomes the bottleneck.
In 2026, technical SEO infrastructure directly shapes how efficiently Googlebot crawls your site, how fast new/updated pages get indexed, and how stable Core Web Vitals remain under real traffic.
Why infrastructure is now an SEO growth constraint
SEO is often presented as an editorial or keyword challenge, but ranking is downstream of reliability: Google can only rank what it can fetch and process consistently.
If your stack is slow or unpredictable, your “best pages” don’t get crawled and refreshed as often as you think especially at scale.
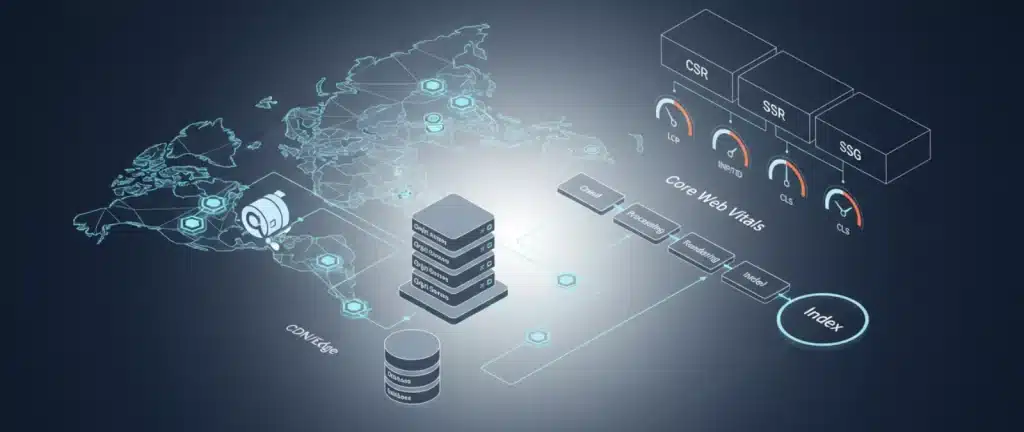
The 3 mechanisms: crawling, indexing, and CWV stability
- Crawling: When responses are slow or error-prone, Googlebot fetches fewer URLs per visit and wastes time on retries.
- Indexing: JS-heavy or unstable rendering pushes pages into slower processing, increasing time-to-index.
- CWV stability: Infrastructure variance creates inconsistent real-user performance across templates, regions, and peak windows.
The infrastructure operating model (what to optimize first)
You don’t “fix performance” one page at a time; you stabilize the system that serves all templates.
The goal is to reduce volatility first, then improve median performance, so crawling and indexing become predictable.
Optimize variance before chasing best-case speed
A low median is meaningless if your site has spikes those spikes are what Googlebot and users experience during real usage.
Treat variance as the primary enemy: it breaks Core Web Vitals consistency and makes crawl behavior unreliable.
Triage by template, not by URL
Infrastructure issues concentrate on specific templates: dynamic listings, faceted pages, internal search, and “assembled” commercial pages.
Start by mapping your templates to business impact (money pages, hubs, long-tail content) and technical sensitivity (DB-heavy, rendering-heavy).
A practical prioritization rule for SEO + engineering
Prioritize work that improves performance and crawl/indexing reliability on templates that drive acquisition and internal linking flow.
Once the system is stable, you can safely invest in deeper architectural changes without constant regressions.
Crawl and index velocity: what Google can’t fetch, it can’t rank
At scale, crawling and indexing are constrained by response time, errors, redirect behavior, and URL explosion.
If Google spends its budget on low-value variants or slow fetches, your important pages get discovered later and refreshed less often.
Reduce crawl waste as a performance multiplier
Facets and parameterized URLs can flood your origin and database with low-value requests.
Controlling crawl waste protects infrastructure and increases the proportion of crawls that hit meaningful pages.
Make routing deterministic (status codes and redirects)
Edge/origin inconsistency, redirect chains, and non-deterministic rules increase latency and waste crawl budget.
Treat redirects and headers as production-critical SEO infrastructure.
Performance fundamentals: TTFB and server health
TTFB is a leading indicator because it measures how fast your system starts delivering HTML before front-end optimizations can help.
Operationally, you manage it by stabilizing response behavior first, then improving the median.
What “good” looks like in 2026 (use as triage)
Use thresholds to prioritize work, not to chase a vanity score.
A common operational target is to keep TTFB under ~800 ms (ideally ~400 ms) for key templates, then reduce variance across regions and peak traffic.
Rendering strategy: make SEO pages exist without JS dependencies
If SEO-critical pages require heavy client-side rendering to “exist,” indexing can be delayed by rendering queue behavior and inconsistent execution.
This is why SSR/SSG are commonly preferred for SEO landing pages and content hubs in B2B contexts.
CSR vs SSR vs SSG: choosing by page type
Use a simple rule: SEO pages should return meaningful HTML immediately.
A pragmatic default is SSG for editorial content, SSR for commercial templates, and CSR for authenticated product surfaces.
Common indexing failure modes
- Content that appears only after hydration or interaction.
- Inconsistent HTML across templates or regions due to edge/origin mismatch.
- Rendering that breaks under load, turning performance variance into indexing variance.
The infrastructure stack: how the pieces work together
Infrastructure is a chain: runtime/server configuration, edge/CDN delivery, database performance, and rendering strategy all compound or cancel each other out.
The winning approach is sequencing improvements so each layer reduces variance and increases reliability.
Server-side performance and configuration
Server performance affects crawl budget, indexing speed, and CWV stability, so you need predictable response behavior under load.
Fix volatility and bottlenecks first, then optimize the fast path.
Edge/CDN layer for stability and global delivery
An edge/CDN layer can stabilize TTFB, reduce errors, and improve crawl efficiency when configured to cache safely and enforce SEO-safe redirects/headers.
It’s not a substitute for a slow database or inefficient backend logic, but it can reduce variance and protect the origin.
Database optimization as an SEO lever
Database optimization stabilizes crawling at scale by fixing indexes, reducing query counts (including N+1 patterns), adding object caching, and controlling faceted URL behavior.
This often delivers site-wide benefits because DB-heavy templates are the first to degrade under load.
Deployment governance: prevent regressions (the part teams skip)
Infrastructure gains disappear when releases change caching, redirects, headers, or rendering behavior without guardrails.
Treat performance work like a controlled release: baseline, gates, and monitoring for the first 72 hours.
Baselines and release gates
Baseline key templates before changes so you can prove impact and detect regressions quickly.
Validate edge/origin consistency for HTML delivery, response codes, and critical headers.
Monitoring after changes (first 72 hours)
Watch TTFB spikes, error rates, and changes in crawling/indexing behavior right after rollout.
If time-to-index worsens after “performance” work, suspect rendering and edge/origin mismatch before blaming content.
The 90-day execution plan (B2B roadmap)
A 90-day plan is long enough to stabilize the system and short enough to keep cross-team focus.
Sequence the work so you stabilize first, then harden architecture.
Weeks 1–2: Diagnostics and baselines
Map templates, measure TTFB variance, and identify DB-heavy and rendering-sensitive routes.
Define your release gates and monitoring so the work doesn’t regress.
Weeks 3–6: Stabilize delivery (TTFB + edge + top templates)
Remove the biggest sources of TTFB spikes on high-impact templates, then stabilize delivery across regions with edge/CDN where appropriate.
Focus on reducing variance under real traffic, not just lab improvements.
Weeks 7–12: Rendering hardening + database + crawl waste control
Harden rendering for SEO-critical routes (SSR/SSG where appropriate) and eliminate top DB bottlenecks with indexing/query/caching work.
Control crawl waste so the system stays stable as you publish more content and scale template complexity.