CDN and edge computing boost SEO by reducing latency, stabilizing TTFB, and improving crawl efficiency. Learn the 2026 playbook to deploy edge caching and rules without breaking indexing.
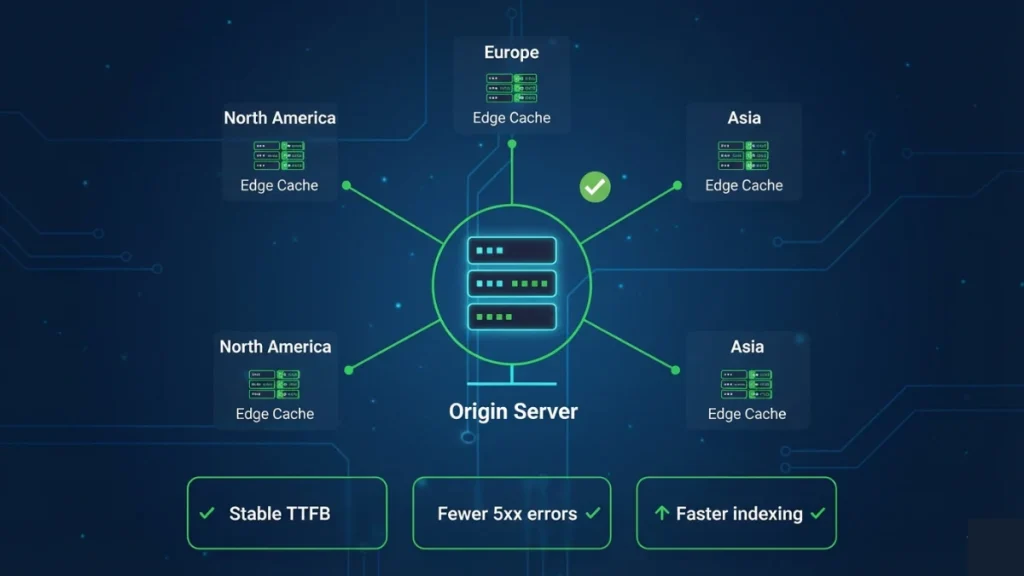
A CDN (Content Delivery Network) improves SEO by serving your pages and assets from servers located closer to users—and closer to Google’s crawler infrastructure—reducing latency and stabilizing performance during traffic spikes. Edge computing goes one step further: it executes logic (caching rules, redirects, personalization, even rendering) at the edge, so the “distance penalty” of a single origin server disappears for most requests.
In B2B SEO, the win is rarely “speed for speed’s sake.” The real advantage is consistency: predictable TTFB, fewer timeout/5xx errors, and less variability across countries and devices. When response times fluctuate, Googlebot becomes conservative with crawl rate, and indexing slows down [[How to optimize server configuration for faster crawling and indexing]]. When response times stay stable under load, crawl efficiency improves and new pages enter the index faster—especially for large sites with many URLs.
A CDN also supports Core Web Vitals by accelerating critical assets (CSS, fonts, images) and by reducing server contention on the origin. If the origin server is busy generating pages, asset delivery still stays fast, which protects LCP and INP in peak moments [[What is server response time (TTFB) and why it matters for SEO rankings?]]. The strategic point for 2026 is simple: treat CDN + edge as an indexing and reliability layer, not only a performance layer, and connect deployment decisions to measurable SEO outcomes [[Server-side performance and rendering: How server configuration impacts SEO rankings in 2026]].
What a CDN changes for crawling, indexing, and rankings
A CDN improves crawl and indexing when it reduces two things Googlebot “hates”: latency and instability. If your origin server occasionally spikes to slow responses or returns intermittent 5xx errors during crawl bursts, Google reduces crawl rate to protect its own resources, and your time‑to‑index increases [[How to optimize server configuration for faster crawling and indexing]]. A CDN absorbs burst traffic (users + bots) and keeps delivery stable, so Googlebot can fetch more URLs per session with fewer failures.
Edge caching also protects performance for international markets. Without a CDN, users and crawlers far from the origin pay a network penalty (higher RTT), which inflates TTFB and pushes LCP upward—especially on mobile networks [[What is server response time (TTFB) and why it matters for SEO rankings?]]. With edge nodes, the HTML (or at least critical assets) can be delivered closer to the request location, reducing the “distance tax” and stabilizing Core Web Vitals across regions.
In 2026, the best CDN setups are not just “cache everything.” They are intentional:
- Cache static assets aggressively (images, fonts, JS/CSS bundles).
- Cache HTML selectively (marketing pages, documentation, blog posts).
- Bypass cache for truly dynamic pages (cart, logged‑in dashboards).
- Use edge rules to normalize redirects and headers (reduces redirect chains and crawl waste).
This is where edge computing matters: it lets you enforce SEO‑safe behavior (headers, redirects, bot handling) without repeatedly hitting the origin [[Server-side performance and rendering: How server configuration impacts SEO rankings in 2026]].
How to implement CDN + edge for SEO (without breaking indexing)
Start with a baseline: measure current global TTFB and error rate on your top landing pages, then roll out CDN features in controlled steps to avoid caching the wrong content.
Step-by-step rollout
- 1) Put the CDN in front (proxy mode) and enable basic caching for static assets (images, CSS/JS, fonts).
- 2) Enable modern protocols (HTTP/2, then HTTP/3 if available) and compression at the edge (Brotli for text assets).
- 3) Define HTML caching rules only for pages that should be identical for all users: blog posts, documentation, landing pages.
- 4) Add edge rules for SEO hygiene: force one canonical host (www or non‑www), normalize trailing slashes, and reduce redirect chains to a single hop.
- 5) Protect the origin with rate limiting for abusive bots, while allowing major crawlers (Googlebot) and your own monitoring.
Common SEO mistakes to avoid
- Caching HTML that contains user‑specific content (pricing by account, geo‑personalization, A/B tests) → risk of wrong indexing.
- Blocking legitimate crawlers with aggressive bot rules → crawl drop + indexing delays.
- Ignoring cache headers → “random” behavior between edge nodes (often visible as higher TTFB).
What to measure after go-live
- Crawl stats (crawl requests/day, response codes, average response time).
- Indexing speed for new URLs (time between publish and “Indexed” in URL inspection).
- CWV stability by country/device (look for reduced variance, not only better averages).
- 5xx rate during peaks (should drop sharply if CDN is doing its job).